The First Open Source Diffusion Audio ASR Model
copy markdown
We taught a diffusion model to listen in six languages.
We trained diffusion-gemma-asr-small, an audio-native ASR model that transcribes through DiffusionGemma's own diffusion decoder. It runs at 3-5× (shorter-longer audio clips) real-time, trains ~42M parameters on top of a frozen 26B backbone, and the hard part had nothing to do with speed.
DiffusionGemma for ASR is the first multilingual audio diffusion ASR model with six languages from one adapter. It's the first built on diffusion whose decoder denoises by uniform, random-token diffusion which initializes the canvas with random vocabulary tokens and anneals them into text, rather than the absorbing <mask> scheme the modern diffusion-LLM crowd uses. And it's the first to do speech recognition by training nothing but a ~42M parameter adapter on a frozen, off-the-shelf diffusion LLM, no decoder trained from scratch, 0.16% of the weights touched. Where it overlaps the closest prior system it already wins: 6.6% vs Whisfusion's 8.3% on LibriSpeech, with a smaller encoder.
What DiffusionGemma actually does
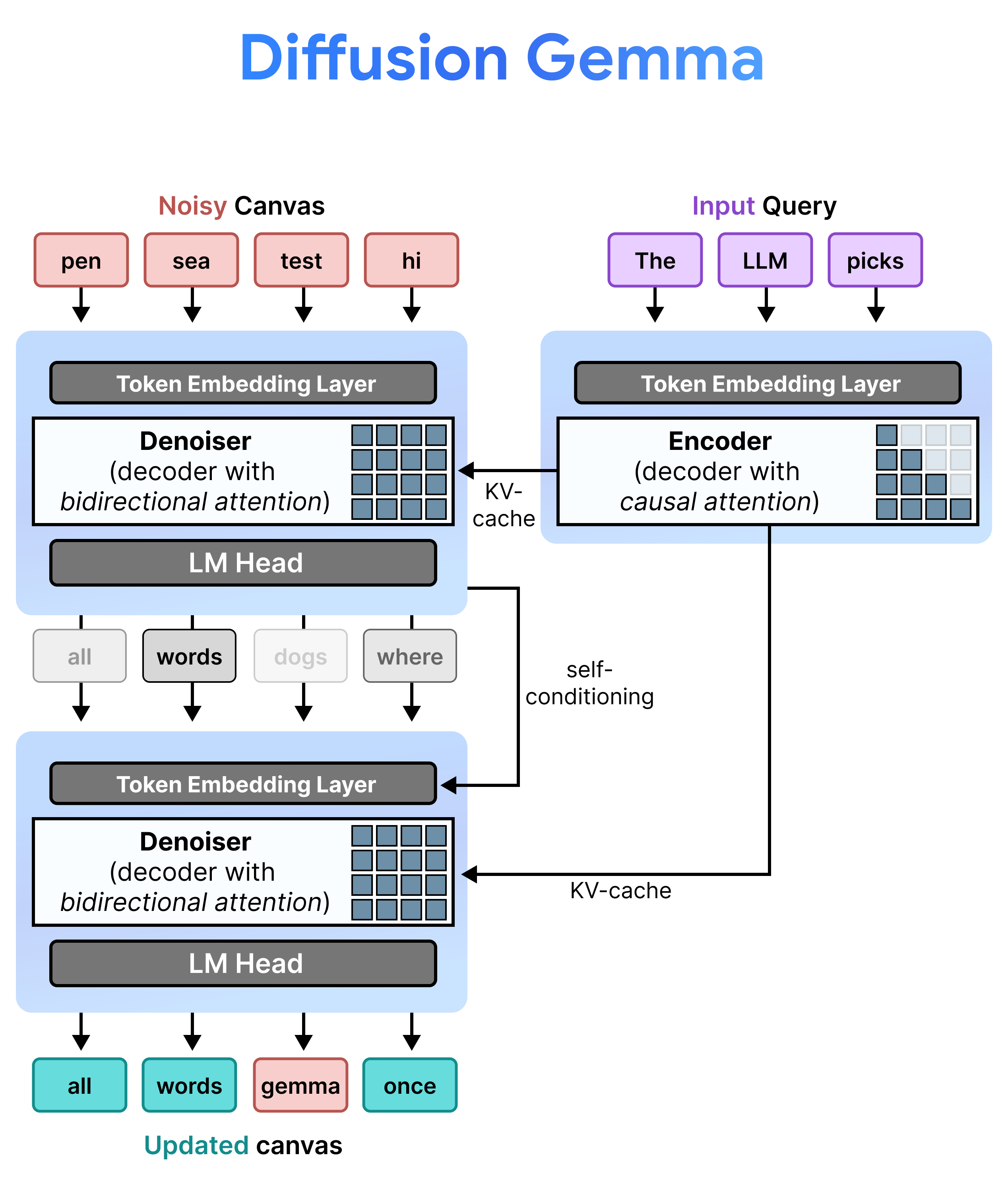
DiffusionGemma is Google's 26B mixture-of-experts model (4B active, 128 experts, top-8) that generates text by discrete diffusion instead of autoregression. The detail that matters: it's uniform diffusion, not the absorbing <mask> kind most people picture.
It starts with a fixed-length canvas 256 token slots filled with random tokens from the vocabulary. Each denoising step, the model looks at the whole canvas at once, keeps the predictions it's confident about, and re-randomizes the rest. After a few steps the noise anneals into text. Training mirrors this: corrupt a fraction γ of a clean sequence to random vocab IDs, ask the model to recover the originals.
Architecturally it's an encoder-decoder with tied weights. The encoder reads the prompt causally into a KV cache; the decoder denoises the canvas bidirectionally, cross-attending to that cache. Out of the box it takes text, images, and video. No audio. That is what we address with our custom architecture.
How do you make a text model hear?
Our initial attempt involved skipping the audio encoder entirely. Gemma's own unified models project raw waveforms straight into the embedding space, so why not feed DiffusionGemma 40ms audio frames and let 26B parameters figure out the acoustics?
It failed completely. A frozen LLM has never seen a spectrogram, the embedding space has no notion of formants or phonemes, and gradient signal through a frozen backbone isn't enough to build an acoustic frontend from scratch. The model learned to ignore the audio and hallucinate fluent, confident nonsense.
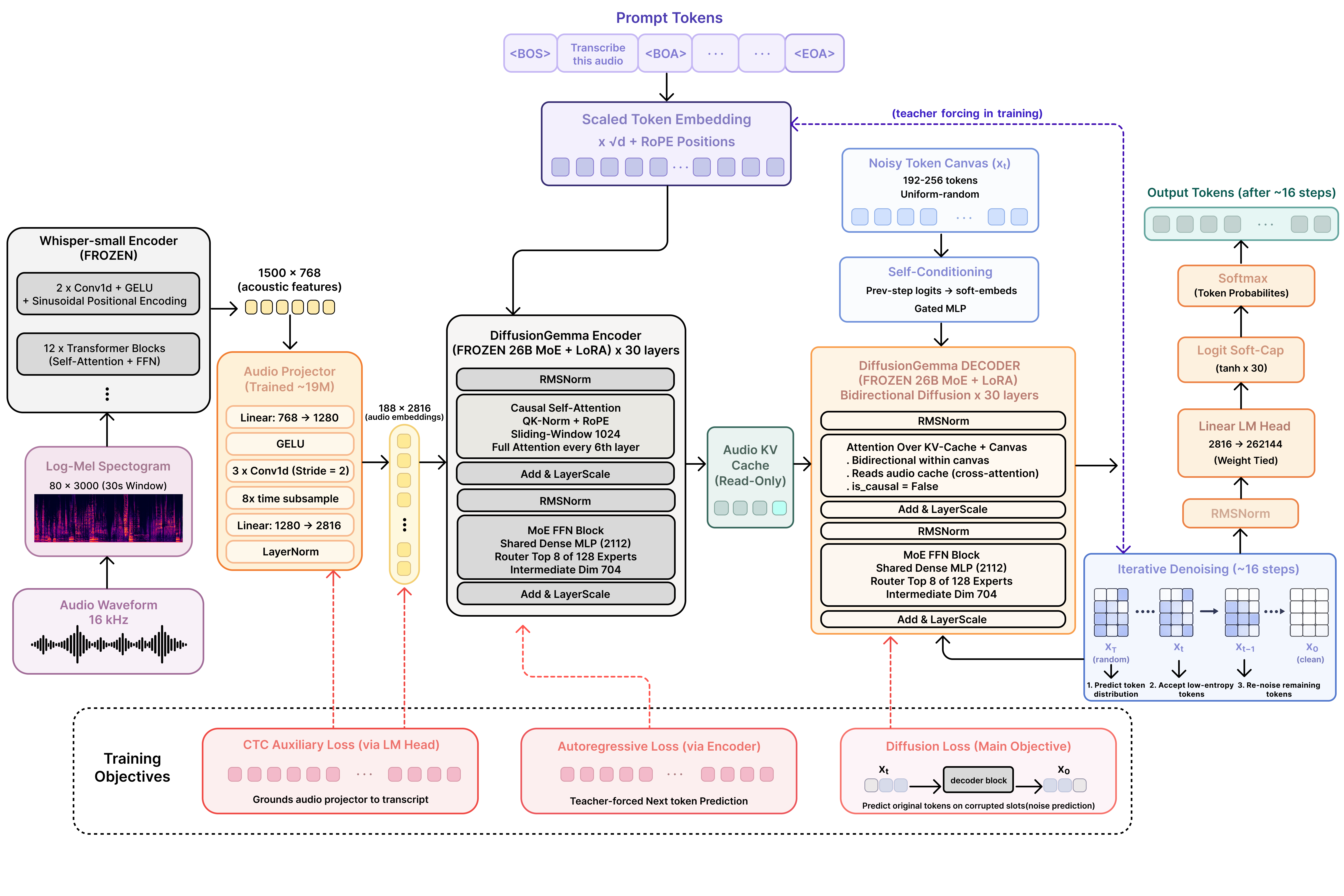
So we introduced a frozen whisper-small encoder, strictly as a feature extractor, not a decoder. Whisper turns 30 seconds of audio into 1500 frames of 768-dim acoustic features. A small trainable projector (a couple of conv layers that subsample 8× plus a linear map to 2816 dims) compresses those into 188 "audio tokens," which we scatter into placeholder slots in the prompt right where the tokenizer already reserves <|audio|> IDs. Add LoRA adapters on the encoder/decoder attention so the backbone can learn to attend to this new modality, and you have a model that, on paper, should transcribe.
It didn't. And the way it didn't is the interesting part.
The chicken-and-egg wall
Training loss flatlined around 8. The auxiliary autoregressive loss sat at 4.00. The model wasn't learning.
We noticed that the failure was circular, the projector starts random, so its output is noise, leading to the attention layers learning to ignore it, therefore almost no gradient reaches the projector, meaning the model never gets to learn anything, causing the results to be output noise. Both training tasks only use the audio when the model's attention actually looks at it, and while attention is ignoring the projector's random output, nothing in training ever tells the projector how to improve.
The unlock: supervise the projector directly
The fix was to give the projector a learning signal that skips attention altogether. We take the projector's 188 audio tokens, run them straight through DiffusionGemma's frozen lm_head, and apply a CTC loss against the transcript.
This sidesteps the whole standoff. CTC forces the audio embeddings to be linearly predictive of the right words in the model's own token space, no attention required. The projector now has a gradient that doesn't depend on anyone trusting it yet. Once its outputs actually mean something, attention has a reason to look, and the diffusion and AR objectives finally catch.
The plateau broke on the first try. CTC loss dropped 24 → 8.6 in 300 steps. Held-out token accuracy climbed off the floor.
The metric that lied
Token accuracy hit 0.50 and CTC loss kept falling and everything looked like grounding. Then upon running a small manual eval sample we noticed repetition.
the the the the the the theThe model was just emitting the most common words in order, with no relationship to what's being spoken in the audio, though the metrics seemed to improve. To solve this we moved to judging it by the transcripts, not the loss. It simply needed far more practice. After enough passes over the data, the output went from the the the to real sentences with the occasional mishearing (tents → tense), and the diffusion decoder itself was doing the transcribing, not leaning on the CTC shortcut.
Where it landed
On LibriSpeech test-clean, English diffusion WER walked down 90% → 52% → 14.6% → 6.6% over ten epochs. Single-digit WER from a frozen 26B backbone, a frozen Whisper encoder, and ~42M trainable parameters, roughly 0.16% of the model.
Followed by this initial training, we further trained it on 5 other languages. Basically by warm starting from the English checkpoint and training on FLEURS across six languages gave us one adapter that handles English, German, French, Spanish, Hindi, and Mandarin. Adding VoxPopuli parliamentary speech on top slightly lowered accuracy on clean, read-aloud speech but noticeably improved it on conversational and accented audio which is a trade off worth making. The model gradually settled into this balance over the course of training.
The shipped small model, measured with the Whisper text normalizer (the Open-ASR / Artificial-Analysis convention, applied to both reference and hypothesis):
| benchmark | metric | score |
|---|---|---|
| FLEURS English | WER | 15.7% |
| VoxPopuli English | WER | 18.5% |
| FLEURS Hindi | CER | 15.8% |
| FLEURS Mandarin | CER | 29.6% |
(We report CER for Hindi and Mandarin on purpose, WER punishes scripts whose word boundaries don't match the reference's segmentation, and quietly overstates the error. Mandarin word-WER read 40% whereas the character error rate is 29.6%. Same transcripts, fairer number.)
The payoff: parallel decoding
Because the diffusion decoder refines the entire canvas at once, transcription cost is set by the number of denoising steps, not the length of the transcript. We swept it:
| steps | FLEURS-en WER | speed |
|---|---|---|
| 8 | 15.7% | 14.9× real-time |
| 16 | 15.6% | 10.3× |
| 32 | 15.2% | 6.5× |
| 48 | 15.6% | 4.7× |
The curve is almost flat. Going from 8 steps to 48 buys you 0.1 point of WER and costs you 3× the latency and on VoxPopuli, more steps made it slightly worse. The model converges in about 8 parallel passes. That's the whole thesis made concrete: ~0.7–1.5s of model time for a ~10-second clip, and it doesn't grow with how much someone says.
How it compares
Against the right peer group i.e. other diffusion or non-autoregressive ASR, our model leads:
| model | approach | LibriSpeech test-clean |
|---|---|---|
| TransFusion (2022) | multinomial diffusion | ~6–7% (proof-of-concept) |
| Whisfusion (Aug 2025) | Whisper-large-v3 + masked diffusion | 8.3% |
| Ours (2026) | Whisper-small + DiffusionGemma | 6.6% |
Lower WER than Whisfusion with a smaller encoder.
Against autoregressive Whisper, the SOTA it trails behind. All Whisper-normalized:
| benchmark | ours | Whisper-small | Whisper-large-v3 |
|---|---|---|---|
| LibriSpeech clean | 6.6% | ~3.4% | ~2.0% |
| FLEURS-en | 15.7% | ~9–10% | ~4–5% |
| VoxPopuli-en | 18.5% | ~9–11% | ~7–10% |
Limitations
Whisper-large-v3 gets ~4–5% on FLEURS English; we're at 15.7%. We're roughly 1.6× the error of whisper-small (the encoder we borrowed) and trailing behind by a margin on large-v3.
The gap is not architecture. It's data. Whisper-large-v3 was trained on something like five million hours of audio; whisper-small on ~680k. This model has seen about 219 hours. That's a three-orders-of-magnitude difference, and the architecture already hit 6.6% on the one domain where we gave it a hundred clean hours. Nothing about the method is broken. It's hungry.
A whisper-large-v3 frontend to raise the feature ceiling, and a lot more audio. The grounding recipe, the CTC unlock, the diffusion decoder, those are done and they work.
Try it
The model is on the Hub at interfaze-ai/diffusion-gemma-asr-small, all of adapter weights, the model code, a runnable inference.py, and a model card. It ships only our ~42M-parameter adapter, the frozen DiffusionGemma and Whisper backbones download from their own repos, under their own licenses.
Three things we're sure of after building this: a frozen LLM can learn to hear if you ground the projector directly instead of through attention, loss curves will lie to you about it, and diffusion decoding makes the length of what someone said stop mattering. The rest is hours of audio.
Built on DiffusionGemma, Whisper.