Vision
Web
Audio
GUI
Compute
Drop a PDF or image, or click to browse
Try one:
Trusted by builders at














Works with any AI SDK
Official SDKs for TypeScript and Python, and chat completion API compatible so it works with every AI SDK or framework out of the box
Interfaze SDK
Vercel AI SDK
LangChain SDK
import { Interfaze, responseFormat } from "interfaze";
import { z } from "zod";
const interfaze = new Interfaze({
apiKey: "<your-api-key>"
});
const IDSchema = z.object({
first_name: z.string().describe("First name on the ID"),
last_name: z.string().describe("Last name on the ID"),
dob: z.string().describe("Date of birth on the ID"),
driver_licence_number: z.string().describe("Driver licence number on the ID"),
});
const response = await interfaze.chat.completions.create({
messages: [
{
role: "user",
content: [
{ type: "text", text: "Extract the details from this ID" },
{
type: "image_url",
image_url: {
url: "https://r2public.jigsawstack.com/interfaze/examples/id.jpg",
},
},
],
},
],
response_format: responseFormat(z.toJSONSchema(IDSchema), "id_schema"),
});
console.log(JSON.parse(response.choices[0]?.message.content ?? "{}"));Deterministic accuracy
Consistent, high-precision results built for repeatable, production tasks.
Verifiable outputs
Confidence scores and bounding boxes you can build real rules on.
Multimodal input
Text, images, audio, files, and video handled in a single model.
Multilingual by default
Understands 100+ languages across every supported modality.
Controllable
Handles complex instructions for workflow with configurable params.
Intelligence
Optimal reasoning capabilities for complex understanding tasks.
Model Comparison
Full breakdown ->
Overview
OCRBench V2
olmOCR
RefCOCO
VoxPopuli-Cleaned-AA
SOB Value Acc
Spider-2.0-Lite
GPQA Diamond
MMMLU
MMMU-Pro
Breakdown
*Each axis is normalized per benchmark so shapes are comparable. VoxPopuli (audio) is excluded here; see its tab for scores.
Verifiable outputs
OCR docs ->
Data you can verify and build rule based systems on with confidence scores, bounding boxes and more

{
"first_name": {
"value": "WESTON COLE",
"confidence": 0.99,
"bounds": {
"top_left": { "x": 866, "y": 701 },
"bottom_right": { "x": 992, "y": 737 }
}
},
"last_name": {
"value": "BAILEY",
"confidence": 1.0,
"bounds": {
"top_left": { "x": 861, "y": 739 },
"bottom_right": { "x": 991, "y": 774 }
}
},
"age": {
"value": 61,
"note": "Derived from date of birth 05/01/1965 as of 2026-06-28",
"confidence": 0.98,
"bounds": {
"top_left": { "x": 865, "y": 1008 },
"bottom_right": { "x": 1063, "y": 1044 }
}
},
"eye_color": {
"value": "BLU",
"confidence": 1.0,
"bounds": {
"top_left": { "x": 1030, "y": 1078 },
"bottom_right": { "x": 1095, "y": 1111 }
}
}
}Multilingual by default
Translation docs ->
Extract and understand text, audio, images in over 100+ languages
zh: 英国每天饮用约100–160百万杯茶,有98%的茶饮者在茶中加入牛奶。
hi: यूके हर दिन लगभग 100–160 मिलियन कप चाय पीता है, और 98% चाय पीने वाले अपनी चाय में दूध मिलाते हैं।
es: El Reino Unido bebe alrededor de 100–160 millones de tazas de té cada día, y el 98 % de los consumidores de té añade leche a su té.
fr: Le Royaume-Uni boit environ 100–160 millions de tasses de thé chaque jour, et 98 % des buveurs de thé ajoutent du lait à leur thé.
de: Das Vereinigte Königreich trinkt etwa 100–160 Millionen Tassen Tee pro Tag, und 98 % der Teetrinker fügen ihrem Tee Milch hinzu.
it: Il Regno Unito beve circa 100–160 milioni di tazze di tè ogni giorno e il 98% degli amanti del tè aggiunge latte al proprio tè.
ja: イギリスでは毎日約100~160百万杯の紅茶が飲まれており、紅茶を飲む人の98%が紅茶に牛乳を加えます。
ko: 영국에서는 매일 약 1억 ~ 1억 6천만 잔의 차를 마시며, 차를 마시는 사람의 98%가 차에 우유를 넣습니다.Built in tools you never need to maintain
STT docs ->
Compute with sandboxes and browse the web with headless browsers
Configurable guardrails and NSFW checks
Guardrails docs ->
Fully configurable guardrails for text and images
S1: Violent Crimes
S2: Non-Violent Crimes
S3: Sex-Related Crimes
S4: Child Sexual Exploitation
S5: Defamation
S6: Specialized Advice
S7: Privacy
S8: Intellectual Property
S9: Indiscriminate Weapons
S10: Hate
S11: Suicide & Self-Harm
S12: Sexual Content
S12_IMAGE: Sexual Content (Image)
S13: Elections
S14: Code Interpreter Abuse
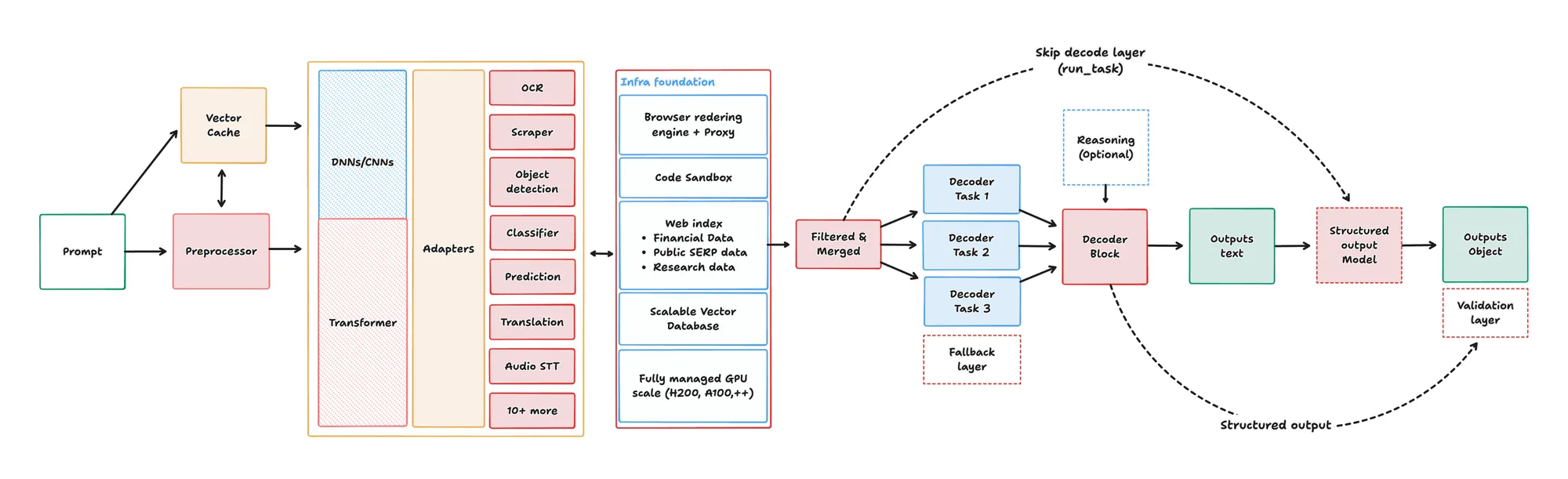
Architecture
Read paper ->
A hybrid Mixture-of-Architecture (MoA) model that combines specialized DNNs/CNNs with a transformer layer to achieve state of the art performance at the highest accuracy and precision while maintaining the flexibility of a traditional LLM.
Specs
Context window
1m tokens
Max output tokens
32k tokens
Input modalities
Text, Images, Audio, File, Video
Reasoning
Available
Pricing
Pricing details ->
Input tokens
$1.50 / MTok
Output tokens
$3.50 / MTok
Caching
Included
Observability & Logging
Coming soon
Latest blog posts
All blogs ->
- An $8 chip just ran a 28.9M-parameter LLM. What else can it do?
- Interfaze is up to 10x cheaper with better token efficiency and caching
- Ask Box: Turn Your Box Account Into a Company Brain
FAQs
All FAQs ->