Interfaze Beta v0.1
copy markdown
Introducing Interfaze, a new model architecture designed for high-accuracy tasks that is deterministic by nature.
Before 2018, DNNs and CNNs were the default for almost any ML task. You trained a model on a task-specific dataset, and it worked great for that learnt data.
These models output confidence scores and other task-related data on every run. That allows developers to build confidence driven systems conditioned on final probabilities/values from the ML models.
Here's an example output from AWS Textract, a traditional deep-learning OCR service.
{
"Type": {
"Text": "TOTAL",
"Confidence": 99.94717407226562
},
"LabelDetection": {
"Text": "Total:",
"Geometry": {
"BoundingBox": {
"Width": 0.09809663146734238,
"Height": 0.0234375,
"Left": 0.36822840571403503,
"Top": 0.8017578125
},
"Polygon": [
{ "X": 0.36822840571403503, "Y": 0.8017578125 },
{ "X": 0.466325044631958, "Y": 0.8017578125 },
{ "X": 0.466325044631958, "Y": 0.8251953125 },
{ "X": 0.36822840571403503, "Y": 0.8251953125 }
]
},
"Confidence": 97.10792541503906
},
"ValueDetection": {
"Text": "$55.64",
"Currency": {
"Code": "USD"
},
"Geometry": {
"BoundingBox": {
"Width": 0.10395314544439316,
"Height": 0.0244140625,
"Left": 0.66837477684021,
"Top": 0.802734375
},
"Polygon": [
{ "X": 0.66837477684021, "Y": 0.802734375 },
{ "X": 0.7723279595375061, "Y": 0.802734375 },
{ "X": 0.7723279595375061, "Y": 0.8271484375 },
{ "X": 0.66837477684021, "Y": 0.8271484375 }
]
},
"Confidence": 99.85165405273438
},
"PageNumber": 1
}Metadata like BoundingBox and Confidence is generated by default on every run. It gives developers a per-output signal they can rely on as threshold or auto-accept high-confidence results and route low-confidence ones to review. The scores are consistent and actionable, which is what production systems actually need.
The glaring problem with DNN/CNN models is that they only know what they were trained on. Introducing a new document type or format means retraining the entire model, which requires specialized ML engineers.
Pros and Cons of DNN/CNN models
| Pros | Cons |
|---|---|
| Cheap to scale (CPU based or small GPU) | Breaks on new data it has never seen |
| High accuracy on trained data (98%-99%+) | High retraining cost with specialized ML engineers required |
| Per-output signals (confidence scores, etc) you can threshold on | Single-dimension task only, not multimodal or flexible |
| Deterministic metadata | Gets outdated quickly |
| Fast inference |
Since 2022, with the launch of ChatGPT and particularly GPT-3.5, transformer-based models have become the standard, and AGI has become the market objective.
These models are great at Natural Language Processing (NLP) & Natural Language Inference (NLI) tasks. They handle human-level nuance and turn words into actions, even for tasks they never saw during training.
Here's an example output from GPT-4.1, a transformer-based model used for OCR tasks.
{
"total": "$55.64",
"currency": "USD"
}Transformer-based models like GPT-4.1 use a user-defined schema to generate structured JSON and return only the required fields. Metadata isn't natively available, and it gets hallucinated if you request it in the output.
LLMs are great at understanding human-level inputs in natural languages and handling a wide range of document formats, even ones they haven't seen. But they're far from doing this consistently and accurately.
Pros and Cons of Transformer models
| Pros | Cons |
|---|---|
| Multi-modal by default | Expensive to scale (Minimum H100 GPU clusters), limited by scaling law, the more compute = better results |
| Flexible on data type and filling in the gaps | Hallucinations with no accuracy measurements |
| Dynamic structured output | Inconsistency (same input doesn't give the same output) |
| Human-level language understanding | Slow to run |
v0.1 Prototype
Can we get the best of both worlds?
DNNs and CNNs for tasks that require high accuracy, paired with transformers for their general nuance and dynamic output generation.
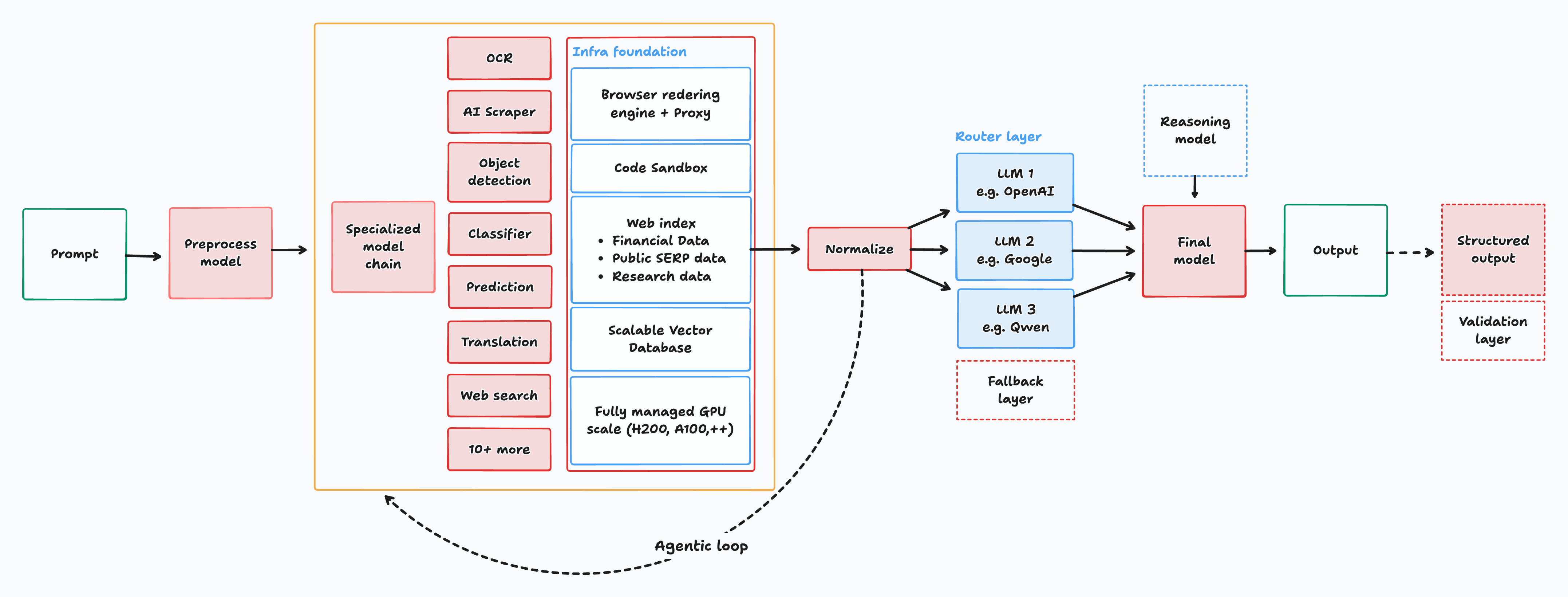
To test this thesis, we built a prototype. We used the tool-calling feature of a standard LLM (Gemini 2.5 Flash) and let it call specialized DNN models: PaddleOCR for OCR, SAM 3 for object detection, Whisper for audio, and more.
We published v0.1 of the experiment and its results in our paper, accepted into IEEE CAI 2026.

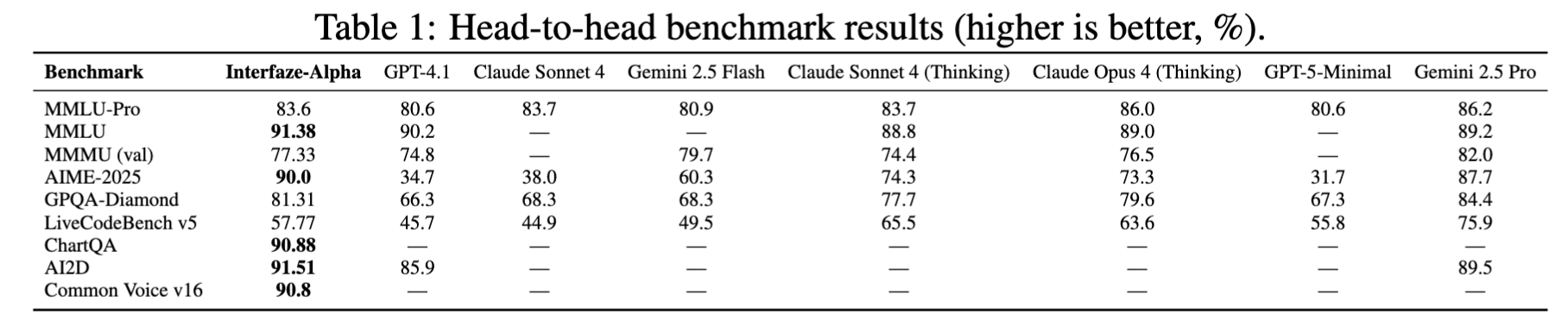
We saw a jump in results, especially on vision-heavy tasks, outperforming both the base Gemini model and Claude Opus 4 on many of them.
This was promising, but we knew the limitations:
- It still relies heavily on the transformer model for tool calling
- The transformer loses a lot of data in context, which drops its accuracy
- It's slow, since tokens are repeated on every tool call and step
- It gets expensive as large token volumes fill up the context
- The transformer still hallucinates significantly
You can find the full prototype code on GitHub.
Prototype to Production hybrid model
The prototype was a good indicator of what's possible: higher-quality output and more verifiable metadata, while keeping the flexibility of transformers.
It's not a perfect implementation. There's still plenty of data loss, slower performance, high cost, and inconsistency on each run.
Even so, it showed a glimpse of what's possible if we trained a model natively from the ground up with a hybrid architecture.
So what's next? The goal for v1 is a native hybrid model where transformers and task-specific DNNs work hand in hand, connected through a shared embedding space so the transformer can read and write task-model representations directly (still an open design question we're prototyping).
To achieve this, we need to accomplish the following:
- Task-specific DNN/CNN models that generate embeddings our transformer can read
- Custom retraining of task-specific encoders for OCR, object detection, audio understanding, diarization, language translation, statistical prediction, and more based on feedback we get from developers
- A transformer trained specifically for these task DNNs while maintaining general understanding
- A transformer that preserves DNN metadata and passes it along to the user
- A powerful decoder for both structured output generation from the user schema and normalization of additional DNN metadata
- Finding the right balance between the weight of the DNNs and reliance on attention
- Optimizing for smaller GPUs and scale
Our goal over the next 3-6 months is to ship a working v1 of our hybrid architecture in production. It should outperform both CNN/DNN models and low-cost production LLMs like the Gemini Flash series, which are commonly used for high-accuracy tasks.
Follow our research and progress
- Join us on Discord
- Follow us on X
- Email us at support@interfaze.ai