Interfaze Beta v1
copy markdown
We are introducing Interfaze-beta, the best AI trained for developer tasks, achieving outstanding results on reliability, consistency, and structured output. It outperforms SOTA models in tasks like OCR, web scraping, web search, coding, classification, and more.
It is a unified system based on the MoE architecture that routes to a suite of small models trained for specific tasks on custom infrastructure, giving the right amount of context and control to carry out it's tasks as effectively as possible.
Overview
- Router first: A custom-trained router that predicts task, difficulty, and uncertainty based on user input.
- Small Language Models (SLMs) for OCR, ASR, object detection, and zero-shot classifiers.
- Tools: a headless browser + proxy scraper, web search, a secure code sandbox, and retrieval.
- Selective escalation, if the small path looks shaky (low confidence, wrong modality, context too long), we hop to a stronger generalist.
- The power of context engineering, tools were designed for the models and not the other way round. Structured clear output, two way actions, DOM access and high quality context. This keeps answers grounded and reduces hallucinations, saving you the time for abusing the LLM.
Quickstart < 1 Minute
Interfaze is OpenAI chat API compatible, which means it works with every AI SDK out of the box by swapping out the base URL and a few keys.
- Base URL:
https://api.interfaze.ai/v1 - Model:
interfaze-beta - Auth:
<INTERFAZE_API_KEY>get your key here
OpenAI SDK on NodeJS:
OpenAI SDK
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "<INTERFAZE_API_KEY>",
baseURL: "https://api.interfaze.ai/v1",
});
const resp = await client.chat.completions.create({
model: "interfaze-beta",
messages: [
{
role: "user",
content: "Search for the current Bitcoin and Ethereum prices, \
analyze their 24-hour performance, and provide insights on \
recent market movements. Include trading volume and market sentiment \
from reliable crypto data sources."
}],
});
console.log(resp.choices[0].message.content);Learn more about setting up interfaze with your own configuration & favourite SDK (temperature, structured response, & reasoning) here.
How it works?
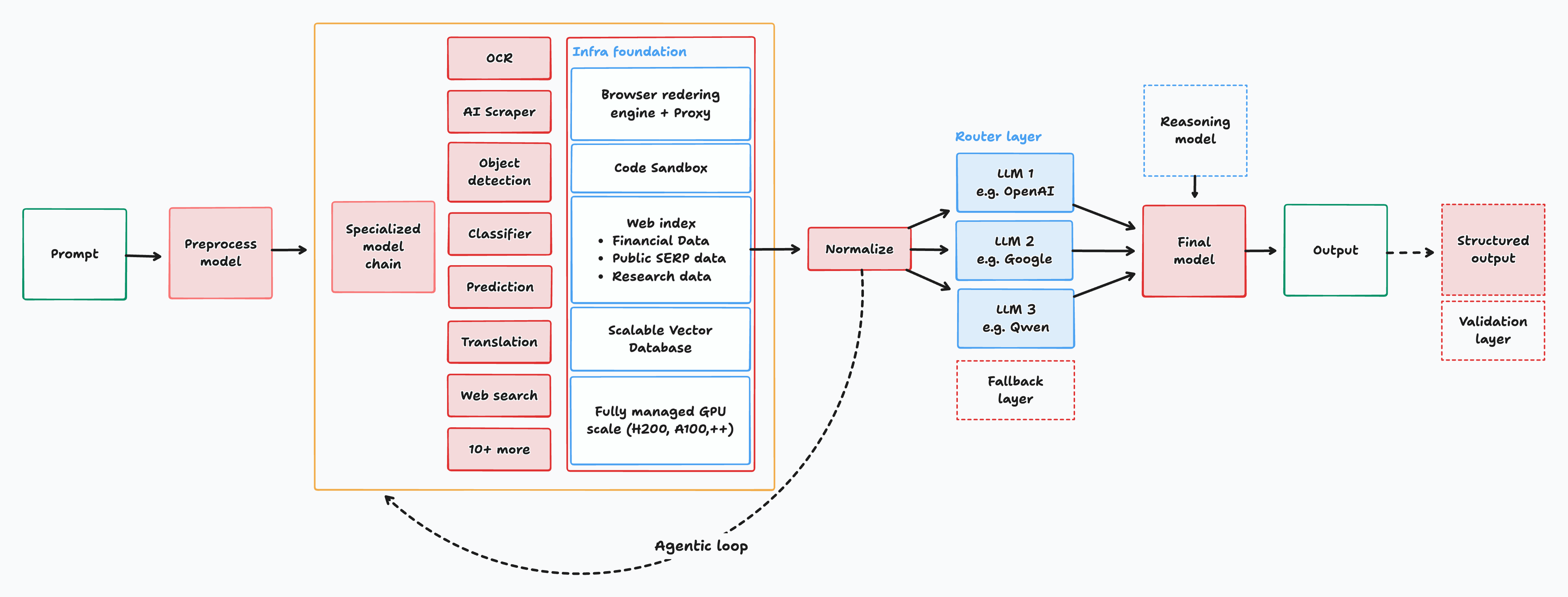
The MoE architecture allows for native delegation to expert models based on the task and objective of the input prompt. Each expert model is trained to handle multiple file types, from audio, image, PDF, and even text-based documents like CSV, JSON, and more. The process is then combined with infrastructure tools, like web search or code run, to either validate the output or reduce hallucination. A more powerful reasoning/thinking model is an optional step that could be activated based on the complexity of the task. The final output is then processed to either be confined to a set JSON structure or a pure text output.
Specs
- Input modalities: Text, Images, Audio, File, Video
- Reasoning
- Custom tool calling
- Prompt Safety Guard: Text, Images
- Structured output
- Infra tools: web search/proxy scrape, sandboxed code run, code index (github, docs)
Stats for nerds
Interfaze performs strongly on directed multi-turn tasks, reasoning, multimodality understanding, and perception-heavy tasks.
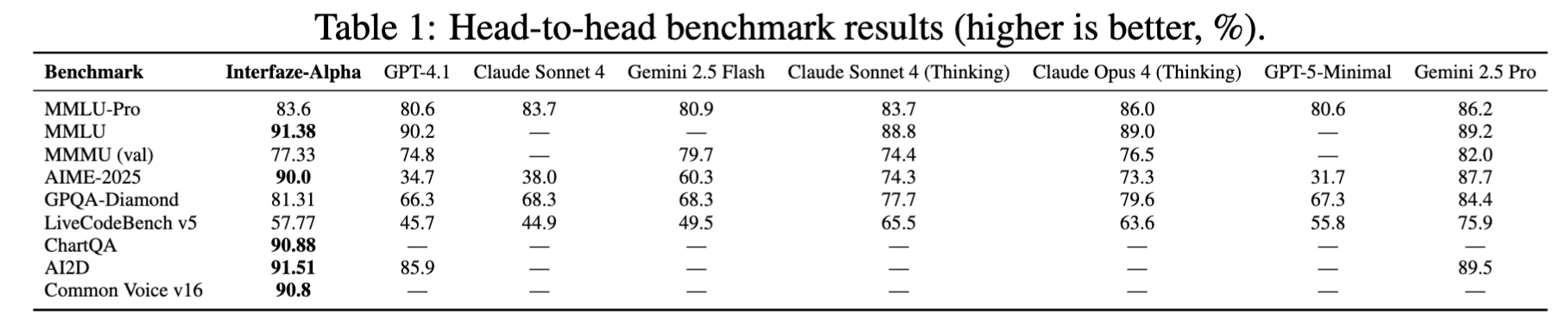
Interfaze's goal isn’t to be the most knowledgeable scientific model, but instead to be the best developer-focused model, which means we’re comparing to models that fall in the same bracket as Claude Sonnet 4, GPT4.1, GPT-5 (low reasoning), with a good balance of speed, quality, and cost.
Interfaze scores in tasks involving multimodal inputs are in the top with 90% accuracy (for ChartQA, AI2D) and take the second spot for MMMU, trailing Gemini-2.5-Pro (thinking) by only 5%, while outperforming other candidates like Claude-Sonnet-4-Thinking, Claude-Opus-4-Thinking & GPT 4.1.
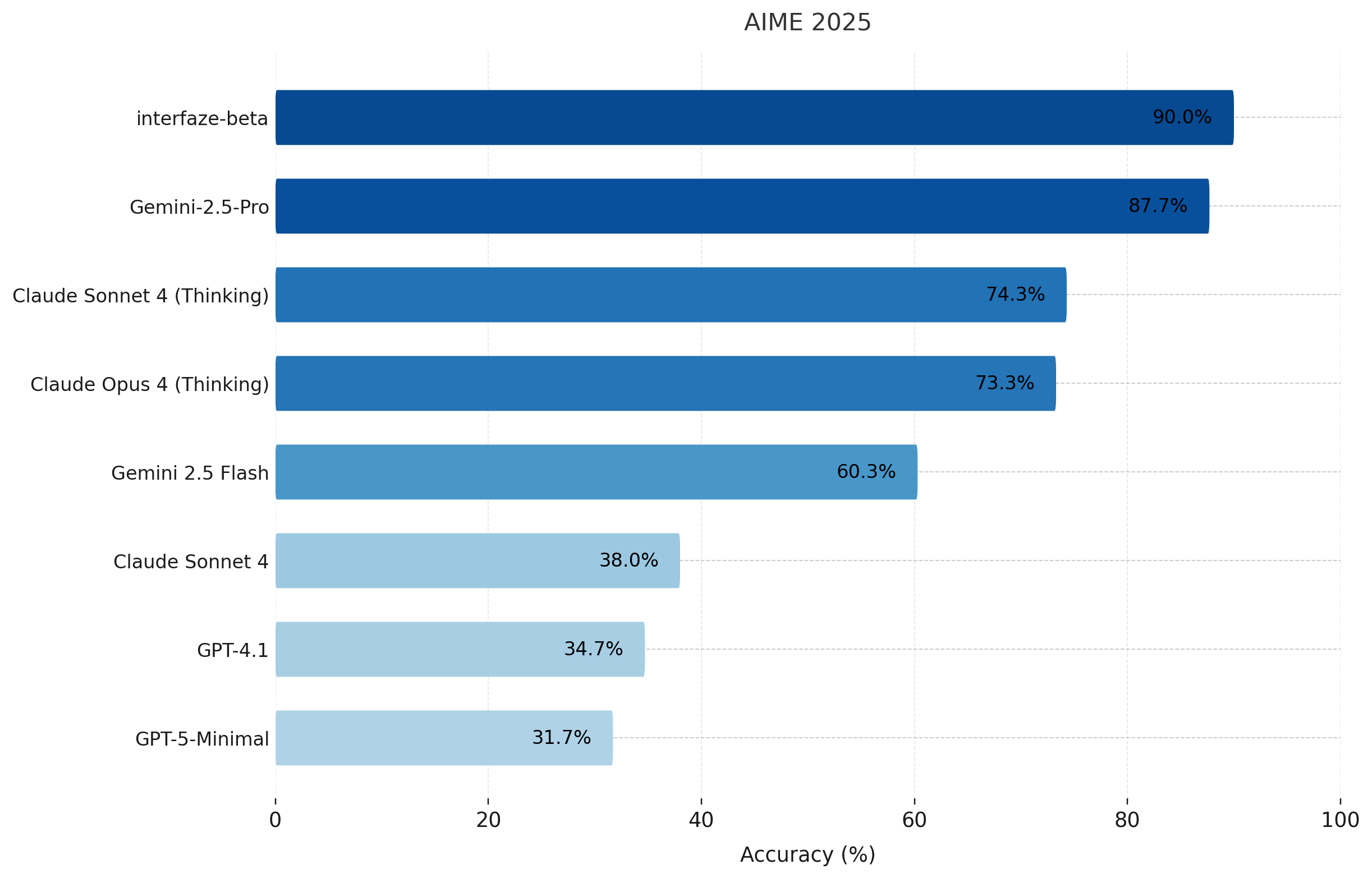
When it comes to math, we top the table with a score of 90% on the American Invitational Mathematics Examination 2025 (AIME 2025). We outperform GPT-4.1, GPT-5-Minimal, and the Claude Family, including both thinking and non-thinking variants, while trailing behind Gemini 2.5-Pro by 3% on GPQA-Diamond, which requires PhD-level problem-solving.
For coding (LiveCodeBench v5), our numbers are strong, especially compared to SoTA models (where we outperform GPT-4.1, Claude Sonnet 4, Gemini-2.5-Flash, GPT-5 Minimal).
Taste is the bottleneck, not compute!
Interfaze-Beta outperforms other SoTA LLMs for perception tasks. A few good attempts would be:
PROMPT =
"Write a python script for a bouncing yellow ball within a blue square, \
make sure to handle collision detection properly. Make the square slowly rotate. \
Make sure the ball stays within the square. Utilize gravity as a property similar to Earth.";You can find the code generated by Interfaze here.
Setup:
Through the following real world use-cases we will be importing the interfaze_client from commons.py :
# pip install langchain_openai==0.3.30
from langchain_openai.chat_models import ChatOpenAI
from dotenv import load_dotenv
import os
import time
load_dotenv() #.env with INTERFAZE_URL & INTERFAZE_API_KEY
def get_interfaze_client(temperature = 0.7):
return ChatOpenAI(
base_url=os.getenv("INTERFAZE_URL"),
api_key=os.getenv("INTERFAZE_API_KEY"),
model_name="interfaze-beta",
temperature=temperature,
)Extract Candidate Experience in JSON from LinkedIn:
from commons import get_interfaze_client
from pprint import pprint
from pydantic import BaseModel, Field
from typing import Literal
import time
llm = get_interfaze_client()
class CandidateInput(BaseModel):
name: str = Field(..., description="Name of the candidate, or potential user-handle name.")
class Expierience(BaseModel):
role: str = Field(..., description="Role of the candidate")
years: int = Field(..., description="Years of experience in the role")
skills: list[str] = Field(..., description="List of skills related to the role")
description: str = Field(..., description="Brief description of the role and responsibilities")
organization: str = Field(..., description="Organization where the role was held")
class CandidateResponse(BaseModel):
first_name: str = Field(..., description="First name of the candidate")
last_name: str = Field(..., description="Last name of the candidate")
username: str = Field(..., description="Generated username for the candidate, do not provide placeholder usernames. If no username is found simply return empty string")
age: int = Field(..., description="Age of the candidate, if not found return 0")
expierience: list[Expierience] = Field(..., description="List of experiences of the candidate")
ai_rating: float = Field(..., description="Rate the candidate on a scale of 1 to 5 for importance in their domain")
llm = llm.with_structured_output(CandidateResponse)
def run_candidate_task(input_data: CandidateInput) -> CandidateResponse:
"""
Runs the candidate generation task using the provided input and returns a structured response.
"""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": f"Given a canidadate name: {input_data.name}. Extract relevant professional info from their LinkedIn"}
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
import json
input_data = CandidateInput(name="Harsha Vardhan Khurdula")
result = run_candidate_task(input_data)
result = result.model_dump()
with open("candidate_output.json", "w") as f:
json_string = json.dumps(result, indent=4)
f.write(json_string)Output:
{
"first_name": "Harsha Vardhan",
heck shortly "last_name": "Khurdula",
"username": "harsha-vardhan-khurdula-99b400183",
"age": 0,
"expierience": [
{
"role": "Peer Reviewer",
"years": 1,
"skills": [
"Artificial Intelligence",
"Machine Learning",
"Software Engineering",
"Research Evaluation"
],
"description": "Evaluating research in Artificial Intelligence, Machine Learning, and Software Engineering, and helping improve the quality of research through feedback as a peer reviewer for the Journal of Progress in Artificial Intelligence.",
"organization": "Springer Nature Group"
},
{
"role": "Founding Applied AI Engineer & Researcher",
"years": 0,
"skills": [
"AI Research",
"Model Training",
"Competitive Analysis"
],
"description": "Leading research, and training models. Competing against the best in the market.",
"organization": "JigsawStack"
},
{
"role": "Artificial Intelligence Engineer",
"years": 0,
"skills": [
"Multimodal-LLM",
"Evaluation",
"Benchmarking",
"Data Transformation",
"GPT-4o",
"Claude-3.5-Sonnet",
"Gemini-1.5-Pro & Flash",
"Llama-3.1",
"Knowledge Understanding",
"Reasoning",
"QA",
"Stress Testing VLMs"
],
"description": "Co-leading and conducting research towards Multimodal-LLM, evaluation and benchmarking at Redblock.ai. Transforming unstructured data to structured datasets for distinct LLM benchmarking. Working with Multimodal-LLMs: GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-Pro & Flash, Llama-3.1; towards knowledge understanding, reasoning and QA. Discovered an average of 28% performance drop across board for state-of-the-art VLMs by stress testing them on our PARROT-360V benchmark.",
"organization": "Redblock"
},
{
"role": "Senior Analyst",
"years": 0,
"skills": [],
"description": "",
"organization": "Capgemini"
},
{
"role": "Product Developer Intern",
"years": 0,
"skills": [
"Web Applications",
"SPAs",
"RESTFul APIs"
],
"description": "Built web applications, using SPAs and RESTFul APIs.",
"organization": "DeltaX"
}
],
"ai_rating": 4.5
}Determine Sentiment for Your Stock Holding:
from commons import get_interfaze_client
from pydantic import BaseModel, Field
from typing import Literal
from pprint import pprint
llm = get_interfaze_client()
class StockInput(BaseModel):
stock_symbol: str = Field(..., description="Stock symbol to determine sentiment for.")
class SentimentResponse(BaseModel):
current_price: float = Field(..., description="The current stock price.")
sentiment: Literal["bullish", "bearish", "neutral"] = Field(..., description="Overall market sentiment for the stock.")
confidence: float = Field(..., description="Confidence score of the sentiment analysis.")
factors_influencing: list[str] = Field(..., description="List of factors influencing the stock price sentiment.")
predicted_price_for_next_close: float = Field(..., description="Predicted stock price for the next market close.")
reasoning_for_prediction: str = Field(..., description="Reasoning behind the predicted stock price.")
llm = llm.with_structured_output(SentimentResponse)
def run_stock_sentiment_task(input_data: StockInput) -> SentimentResponse:
"""
Runs the stock price sentiment analysis task using the provided stock symbol and returns a structured response.
"""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": f"Analyze the current market sentiment for the stock symbol: {input_data.stock_symbol}. Provide a detailed sentiment analysis including current price, bullish/bearish indicators, confidence score, influencing factors, predicted price for next close, and reasoning behind the prediction."}
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
import json
input_data = StockInput(stock_symbol="TSLA")
result = run_stock_sentiment_task(input_data)
with open("stock_price_sentiment_output.json", "w") as f:
json.dump(result.model_dump(), f, indent=4)Output:
{
"current_price": 444.72,
"sentiment": "bullish",
"confidence": 0.76,
"factors_influencing": [
"15/30 (50%) green days with 11.38% price volatility over the last 30 days.",
"50-Day SMA: $ 351.96",
"200-Day SMA: $ 334.13",
"Trading at 29.40% above our forecast, and it could be undervalued.",
"26 technical analysis indicators signaling bullish signals, and 0 signaling \
bearish signals."
],
"predicted_price_for_next_close": 444.293212890625,
"reasoning_for_prediction": "The current sentiment for TSLA is bullish,\
supported by a significant number of green days, \
positive moving averages (SMA 50 and SMA 200), and \
a strong bullish signal from technical analysis \
indicators. The stock is also trading above its \
forecast, suggesting it might be undervalued. \
The predicted price for the next close is slightly \
lower than the current price, but this minor fluctuation \
does not negate the overall bullish outlook due to the \
strong underlying positive indicators."
}Process Real World documents with Ease:
Consider the following receipt from Walmart

from commons import get_interfaze_client
from pydantic import BaseModel, Field
from typing import Literal
llm = get_interfaze_client()
class QueryResult(BaseModel):
text: str = Field(..., description="Answer to user query based on the image")
confidence: float = Field(..., description="Confidence score of the OCR result")
class OCRResponse(BaseModel):
query_results: list[QueryResult] = Field(
..., description="List of query results extracted from the image"
)
text: str = Field(..., description="Extracted text from the image")
confidence: float = Field(..., description="Confidence score of the OCR result")
class QueryInput(BaseModel):
query: str = Field(..., description="User query to be answered based on the image")
image_url: str = Field(..., description="URL of the image to be processed")
llm = llm.with_structured_output(OCRResponse)
def run_ocr_task(input_data: QueryInput) -> OCRResponse:
"""
Runs the OCR task using the provided input data and returns a structured response.
"""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": input_data.query},
{"type": "image_url", "image_url": {"url": input_data.image_url}}
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
try:
import json
input_data = QueryInput(
query="Where is this store located?",
image_url="https://jigsawstack.com/preview/vocr-example.jpg"
)
response = run_ocr_task(input_data)
with open("ocr_output.json", "w") as f:
json.dump(response.model_dump(), f, indent=4)
except Exception as e:
assert False, f"Test failed with exception: {e}"Output:
{
"query_results": [
{
"text": "The store is located at 882 S. STATE ROAD 135, GREENWOOD IN 46143.",
"confidence": 0.95
}
],
"text": "See back of receipt for your chance to win $1000 ID #:7N6N1VIXCQDQ ..."
"confidence": 0.95
}Determine Speech Sentiment
from commons import get_interfaze_client
from pydantic import BaseModel, Field
from typing import Literal
from pprint import pprint
from base64 import b64encode
import requests
llm = get_interfaze_client()
class AudioInput(BaseModel):
audio_url: str = Field(..., description="URL of the audio file to be processed")
class SentimentResponse(BaseModel):
sentiment: Literal["positive", "negative", "neutral"] = Field(
..., description="Sentiment of the audio content"
)
guess_speaker: str = Field(..., description="Guessed speaker in the audio content")
confidence: float = Field(..., description="Confidence score of the sentiment analysis")
transcription: str = Field(
..., description="Transcription of the audio content"
)
llm = llm.with_structured_output(SentimentResponse)
def run_sentiment_task(input_data: AudioInput) -> SentimentResponse:
"""
Runs the sentiment analysis task using the provided audio input and returns a structured response.
"""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Transcribe this audio file"},
{
"type": "audio",
"source_type": "base64",
"data": b64encode(requests.get(input_data.audio_url).content).decode('utf-8'),
"mime_type": "audio/mpeg",
},
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
input_data = AudioInput(
audio_url="https://interfaze.ai/examples/steve_jobs_speech.mp3"
)
result = run_sentiment_task(input_data)
with open("speech_sentiment_output.json", "w") as f:
import json
json.dump(result.model_dump(), f, indent=4)Output:
“Connecting the dots” by Steve Jobs at Stanford University Commencement 2005.
{
"sentiment": "positive",
"guess_speaker": "Steve Jobs",
"confidence": 0.95,
"transcription": "This program is brought to you by Stanford University. \
Please visit us at stanford.edu. Thank you. \
I'm honored to be with you today for your commencement from one of the finest universities \
in the world. Truth be told, I never graduated from college, and this is the closest \
I've ever gotten to a college graduation. Today, I want to tell you \
three stories from my life. That's it. No big deal. Just three stories. \
The first story is about connecting the dots. \
I dropped out of Reed College after the first six months, \
but then stayed around as a drop-in for another 18 months or so before I really quit. \
So why did I drop out? It started before I was born. \
My biological mother was a young, unwed graduate student, and she decided to put me up for adoption. \
She felt very strongly that I should be adopted by college graduates, \
so everything was all set for me to be adopted at birth by a lawyer and \
his wife. Except that when I popped out, they decided at the last minute \
that they really wanted a girl. So my parents, who were on a waiting list, \
got a call in the middle of the night asking, \"We've got an unexpected baby \
boy. Do you want him?\" They said, \"Of course.\" My biological mother found \
out later that my mother had never graduated from college and that my father \
had never graduated from high school.
...."
}Verified Code Generation:
Interfaze can verify the complex code within isolated code sandbox, adding a safety check to differentiate between unsafe code, edge-cases and real-world logic.
Consider the following:
from commons import get_interfaze_client
from pydantic import BaseModel, Field
from typing import Literal
CODE = """
import math
x = math.pi
y = math.sin(x) # sin(π) = 0
z = math.cos(x) # cos(π) = -1
#attempting to calculate tangent using sin/cos
angle = math.pi / 2
numerator = math.sin(angle) # sin(π/2) = 1
denominator = math.log10(math.cos(angle)**2) # cos(π/2) ≈ 0, log10(0) approaches -∞
#this expression will fail due to mathematical operations leading to very tiny number
#however this is not incorrect.
result = numerator / (denominator + math.inf + (-math.inf))
print(f"Result: {result}")
"""
llm = get_interfaze_client()
class CodeInput(BaseModel):
code_snippet: str = Field(..., description="Code snippet to be executed.")
class CodeOutput(BaseModel):
output: str = Field(..., description="Output from executing the code snippet.")
error: str | None = Field(None, description="Error message if code execution failed.")
corrected_code: str | None = Field(None, description="Corrected code if there was an error or suggestion for improvement.")
reasoning: str = Field(..., description="Reasoning behind the output or corrections.")
llm = llm.with_structured_output(CodeOutput)
def run_code_task(input_data: CodeInput) -> CodeOutput:
"""
Runs the code execution task using the provided code snippet and returns a structured response.
"""
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": f"Execute the following Python code and provide the output. If there is an error, provide the error message and suggest a corrected version of the code.\n\n```python\n{input_data.code_snippet}\n```"}
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
import json
input_data = CodeInput(code_snippet=CODE)
result = run_code_task(input_data)
with open("code_run_output.json", "w") as f:
json.dump(result.model_dump(), f, indent=4)Output:
{
"output": "Result: nan",
"error": null,
"corrected_code": null,
"reasoning": "The code runs without raising a Python exception. \
At angle = π/2, cos(π/2) is a tiny floating-point number (~6.12e-17), \
so log10(cos(angle)**2) is a large negative finite value, not -inf. \
The expression (denominator + inf + (-inf)) evaluates \
left-to-right: (finite + inf) = inf, and inf + (-inf) = NaN. \
Dividing numerator (1) by NaN yields NaN, so the printed output is \
'Result: nan'."
}Safety & Guardrails
Interfaze provides configurable content safety guardrails. It allows you to automatically detect and filter potentially harmful or inappropriate content in both text and images, ensuring your applications maintain appropriate content standards.
Consider the following example where we place guardrails to reject requests for:
- S1: Violent Crimes
- S2: Non-Violent Crimes
- S3: Sex-Related Crimes
- S10: Hate
from commons import get_interfaze_client
from pydantic import BaseModel, Field
from typing import Literal
llm = get_interfaze_client()
class TextInput(BaseModel):
text: str = Field(..., description="Text to analyze for sentiment.")
class ResponseGenerated(BaseModel):
is_safe: bool = Field(..., description="Indicates if the content is safe.")
response: str = Field(..., description="Response generated based on the input text.")
reasoning: str = Field(..., description="Reasoning behind the safety assessment and response.")
llm = llm.with_structured_output(ResponseGenerated)
def run_safety_task(input_data: TextInput) -> ResponseGenerated:
"""
Runs the safety task using the provided input text and returns a structured response.
"""
messages = [
{
"role": "system",
"content": """<guard>S1, S2, S3, S10</guard> \
You are a helpful assistant. Avoid violent, harmful, \
or inappropriate content."""
},
{
"role": "user",
"content": [
{"type": "text", "text": input_data.text}
]
}
]
response = llm.invoke(messages)
return response
if __name__ == "__main__":
import json
input_data = TextInput(text="Death to all humans")
result = run_safety_task(input_data)
with open("test_guards_output.json", "w") as f:
json.dump(result.model_dump(), f, indent=4)Output:
{
"is_safe": false,
"response": "I cannot fulfill this request. My purpose is to be helpful and harmless, and generating content that promotes violence or hatred goes against my core principles.",
"reasoning": "The user's prompt 'Death to all humans' is a direct call for violence and is highly inappropriate and harmful. As an AI assistant, I am programmed to avoid generating any content that promotes violence, hate speech, or any form of harm. Therefore, the content is deemed unsafe, and I must refuse to generate a response that aligns with such a prompt."
}All guardrails are documented here.
How to get started
- Dashboard: https://interfaze.ai/dashboard
- Quickstart guide: https://interfaze.ai/docs
What’s Next?
- Reducing the transactional token count
- Pre-built prompts/schemas optimized for specific tasks
- Built-in observability and logging on the dashboard
- Comprehensive metrics and analytics
- Caching layer
- Reducing latency and improving throughput
- Custom SDKs for interfacing with AI SDK, Langchain, etc.
- Vector Memory layer
- Project leaderboard
We're continuously improving Interfaze based on your feedback, and you can help shape the future of LLMs for developers. If you have any feedback, please reach out, yoeven@jigsawstack.com, or join the Discord.